La 6ème édition de la conférence SemWeb.Pro, organisée par LogiLab le 22 novembre à Paris, a réuni de nombreux acteurs de la communauté des professionnels du web sémantique.
L’édition 2017 a montré la maturité de l’utilisation des techniques du web sémantique.
Les témoignages ont porté sur des applications opérationnelles dans des domaines variés comme la valorisation de contenus stockés dans différents silos de données pour RTL Belgique, la publication et le partage des textes législatifs pour le journal officiel du Luxembourg, le « push » de conseils de mise en garde pour la bonne utilisation des médicaments dans l’application de l’éditeur Vidal, etc.
Et aussi des initiatives publiques comme la visite guidée à distance du musée de la guerre, l’exploitation de la masse des données des Paradise Papers par le filtrage des relations, l’accès à une base d’informations sur les partitions, la musique et les événements liés. Sans oublier les projets de recherche et les plateformes de développement.
A l’évidence les domaines d’applications sont vastes et les résultats au rendez-vous avec un délai de réalisation court. Ces expériences témoignent du potentiel inégalé de la connexion des données.
Six enseignements de la SemWeb. Pro 2017 à partager !
Enseignement n°1 : Les liens, les ressources les plus précieuses !
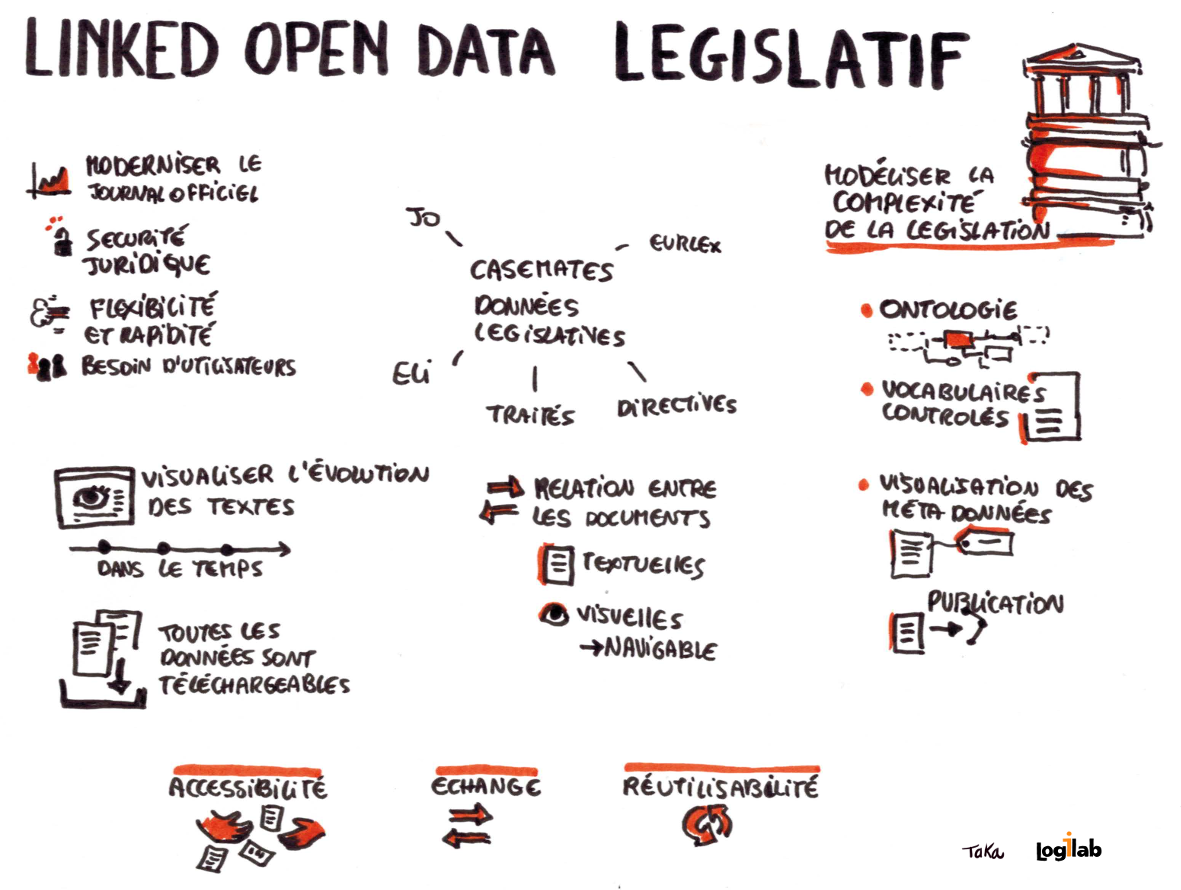
John Dann du Journal Officiel du Grand Duché du Luxembourg mentionne que l’utilisation du web sémantique a permis de réduire le budget de 70% tout en apportant des fonctions de connexion éminemment appréciées des utilisateurs.
« Ce que les utilisateurs apprécient le plus ce sont les relations », dit John. Il souligne que l’ontologie et le vocabulaire commun sont le fondement de l’application. Sans ontologie, pas de relations entre les données !
Vincent Vialard de la société Derivo témoigne du rôle clef de l’extraction des relations pour l’exploitation de grandes masses de données.
SemSpect permet de naviguer sur la masse des données récoltée par les Paradise Papers ; 2,6 Téraoctets de données, représentant 151 000 adresses, 500 000 entités et 4,5 millions de relations. Cette application a été utilisée par les journalistes du consortium d’investigation.
Bravo à Derivo pour cette démonstration live de navigation par les graphes de relations qui permet l’accès à de nouvelles connaissances et pas des moindres !
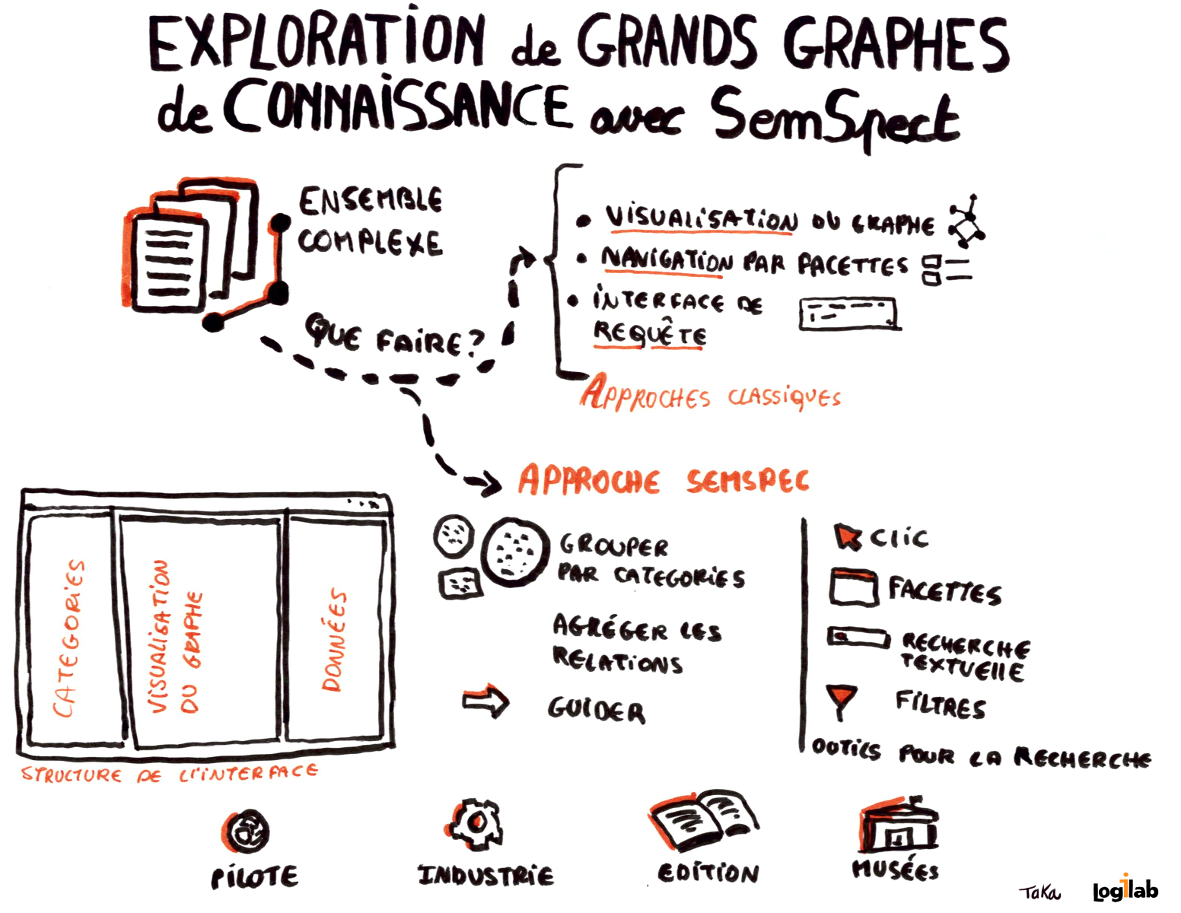
Enseignement n°2 : Libérez les données !
Libérer les données, c’est les réconcilier pour mieux les valoriser.
Cédric Klein et Guillaume Rachez de Perfect Memory l’illustrent avec la mise en œuvre d’un modèle évolutif, indépendant d’une technologie, qui permet de valoriser les capsules de contenus de RTL Belgique, quel que soit le média pour lequel la capsule a été élaborée et le silo de données dans laquelle elle est conservée. Une interface intuitive donne accès aux capsules et permet de les enrichir.
La plateforme Perfect Memory est utilisée par plusieurs grands médias.
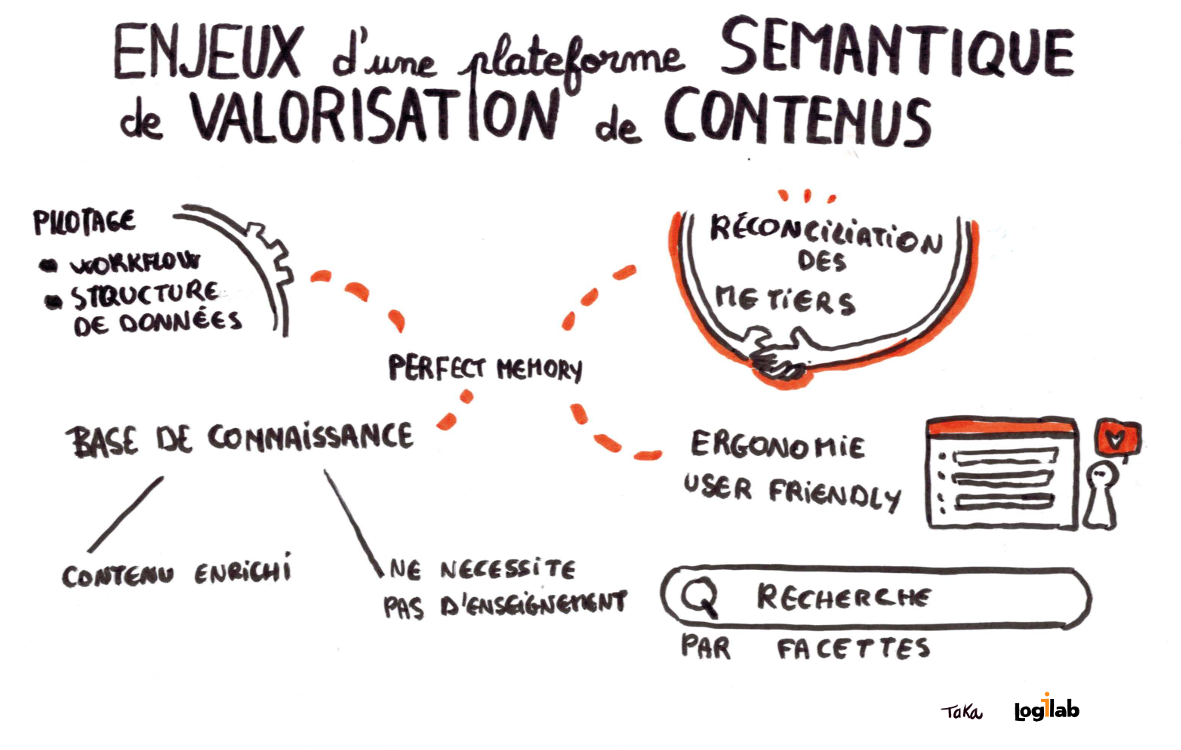
Enseignement n°3 : les ontologies, lien entre les objets du monde réel, leurs représentations digitales et les processus
Dimitris Kiritsis de l’Ecole Polytechnique Fédérale de Lausanne, comme de nombreux intervenants, insiste sur le rôle essentiel de l’ontologie.
L’ontologie fait le lien entre les objets du monde réel, leurs représentations et la mobilisation des connaissances dans les processus opérationnels.
Dimitris contribue dans le cadre des projets d’industrie du futur, notamment le projet européen FALCON, à définir le cadre qui permet de créer ces ontologies.

Enseignement n°4 : Les standards du web sémantique au cœur de la normalisation et de l’industrie du futur
Philippe Magnabosco de l’AFNOR, Christophe Mouton, EDF, Yves Keraron d’ISADEUS, témoignent des fortes synergies entre les initiatives de normalisation de l’ISO, l’AFNOR, les standards du web sémantique et les besoins des industriels.
Collaborer, chercher à faire ce qui se fait mieux, prendre en compte les feedbacks
« La normalisation n’est pas obligatoire, c’est un moyen d’apporter de nouveaux produits, services dans des conditions acceptables » indique Philippe. « Pas de maquette numérique, sans relations entre les données », dit Christophe. Yves mentionne des projets européens d’usine du futur basés sur ces standards comme FALCON, récolte des informations d’usage du produit pour les réinjecter dans le processus de conception, et UPTIME, plateforme de maintenance prédictive. « Prendre en compte les compétences en technos sémantiques et ne pas oublier la gestion du changement », conclut Yves.

Enseignement n°5 : Modéliser au niveau nécessaire … selon les besoins des cas d’emploi
Il n’est pas nécessaire de modéliser les boutons de manchette des vêtements des soldats pour bâtir une application de visite interactive d’un musée de la première guerre mondiale. Michel Buffa, INRIA
Les usages des données ne peuvent être entièrement prédits à l’avance néanmoins les modèles initiaux doivent correspondre aux besoins des cas d’emploi.
Enseignement n°6 : Le web sémantique pour les masses !
Le web sémantique pour le plus grand nombre, c’est ce qu’offre Kevin Dunglass et la société les Tilleuls, avec l’API Platform.
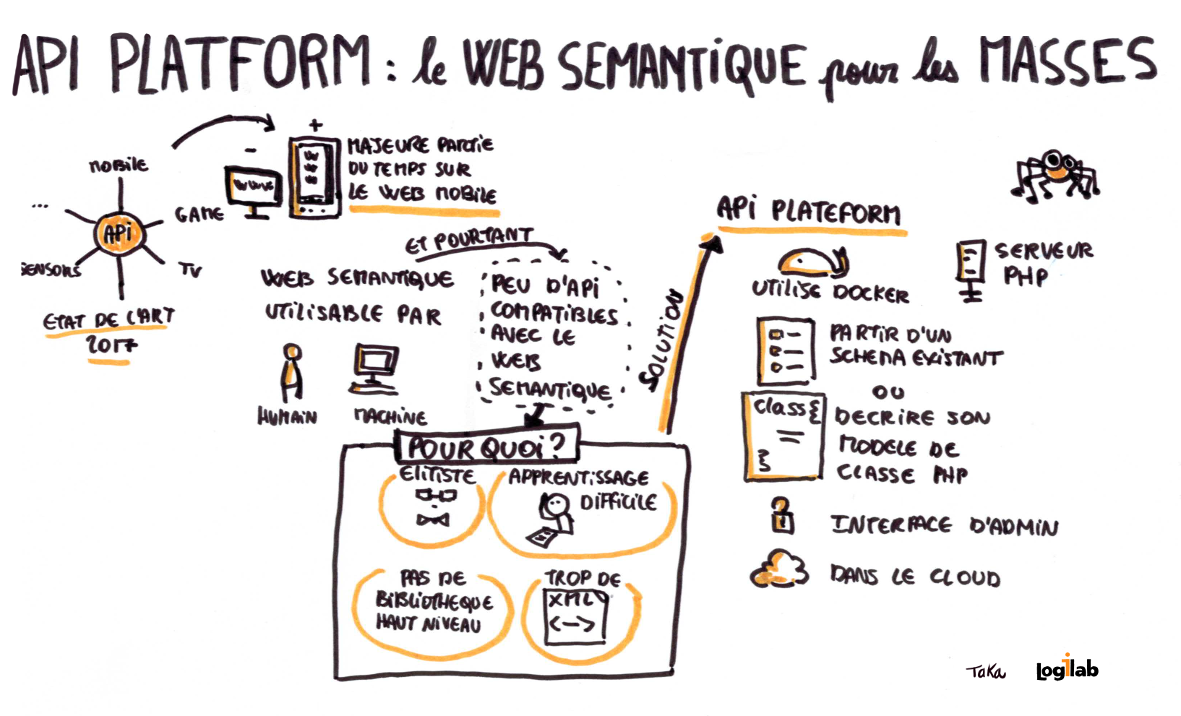
L’adoption par les développeurs du web sémantique passe par des langages et des API : JSON-LD, basé sur JSON, est un format d’échange de données facile à implémenter. L’API Platform est un framework de Linked Data construit sur le framework Symfony ; il a été élu meilleur outil 2017 sur Symfony. Félicitations à l’équipe les Tilleuls !
Un pas de plus pour la concrétisation du Web des données avec Nicolas Chauvat de Logilab.
Logilab développe en Open Source un navigateur Web pour les données qui permet d’afficher les données incluses dans des pages HTML avec la vue choisie par l’utilisateur. Bravo pour cette initiative qui prolonge CubicWeb !
Beaucoup d’autres enseignements et de partages au cours de la conférence comme l’utilisation des ontologies pour sécuriser le développement d’applications, présenté Michel Vanden Bossche d’ODASE Ontologies. Et des débats techniques passionnants autour de SHACL, nouvelle recommandation du W3C pour la validation des données et complémentaire de OWL, avec Thomas Francquart.
Autour de l’espace café, des posters ont permis de faire connaître des applications de qualité qui ont complété ce riche agenda.
Conclusion
SemWeb.Pro a une fois de plus démontré les bénéfices de l’utilisation concrète des technologies du web sémantique pour la valorisation de données de sources hétérogènes de grands volumes.
Les outils et plates-formes existent pour une utilisation massive de ces technologies, déjà mises en œuvre dans de nombreux domaines.
Libérer les données, c’est aussi lever les obstacles organisationnels, et l’opportunité de libérer la créativité, favoriser la transparence, développer l’innovation !
Un grand merci aux organisateurs de SemWeb.Pro 2017 pour cette journée riche et conviviale, et à Juliette de Logilab pour les illustrations des conférences.
Le programme de SemWeb.Pro 2017 et les contenus des conférences sont disponibles sur :
http://www.semweb.pro/semwebpro-2017.html

Isabelle Tanguy et Yves Keraron